Forkurs: Kodoner er "ord" i den genetiske koden.
Et kodon består av tre byggesteiner i DNA eller RNA, kalt nukleotider, som sammen bestemmer hvilken aminosyre som skal brukes når cellen lager proteiner.
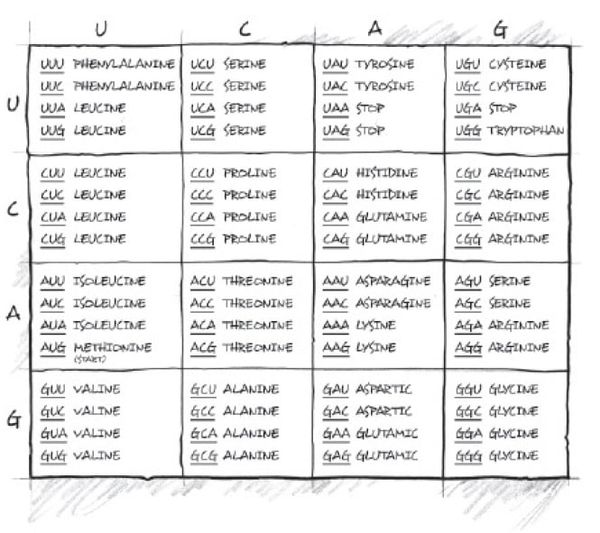 For eksempel: RNA-kodonet AUG betyr vanligvis:
For eksempel: RNA-kodonet AUG betyr vanligvis:
start på proteinsyntesen; aminosyren metionin
Siden det finnes fire ulike nukleotider i RNA (A, U, C og G), og kodoner består av tre tegn, finnes det:
4^3=64 mulige kodoner.
Disse 64 kodonene koder for:
20 vanlige aminosyrer; startsignaler; stopp-signaler
Hvordan fungerer det?
Prosessen skjer slik: DNA inneholder genetisk informasjon.
Et gen kopieres til budbringer-RNA (mRNA).
Ribosomet leser mRNA tre og tre baser om gangen - altså ett kodon av gangen.
Hvert kodon kobles til en bestemt aminosyre.
Aminosyrene settes sammen til et protein
Bilde 1. Mulige kodon-kombinasjoner og tilhørende aminosyre
Eksempel:
mRNA-kodonAminosyreAUGMetioninUUUFenylalaninGGCGlysin
Hvorfor er kodoner viktige?
Kodoner er selve oversettelsessystemet mellom: genetisk informasjon og biologisk struktur/funksjon
De fungerer derfor som en slags biologisk "kodebok" som gjør at cellene kan bygge proteiner nøyaktig. Mange biologer omtaler dette som den genetiske koden, fordi bestemte symbolkombinasjoner konsekvent svarer til bestemte aminosyrer eller signaler.
Den genetiske koden: To nivåer til av optimalisering
Jonathan McLatchie 6. mai 2026. Oversatt herfra
 I to tidligere artikler (her og her) vurderte vi to måter den genetiske koden er svært optimalisert på, for minimering av feil fra punktmutasjoner og rammeskift. I dette tredje innlegget vil jeg vurdere to ytterligere nivåer av finjustering.
I to tidligere artikler (her og her) vurderte vi to måter den genetiske koden er svært optimalisert på, for minimering av feil fra punktmutasjoner og rammeskift. I dette tredje innlegget vil jeg vurdere to ytterligere nivåer av finjustering.
Tilrettelegging av overlappende kodesekvenser
Bilde 2. DNA -digitalt representert
I en artikkel fra 2007 publisert i Genome Research viser Itzkovitz og Alon at den universelle genetiske koden er strukturert på en slik måte at den "tillater vilkårlige sekvenser av nukleotider innenfor kodende sekvenser mye bedre enn de aller fleste andre mulige genetiske koder".(1) De rapporterer:
"Vi finner at den universelle genetiske koden kan tillate vilkårlige sekvenser av nukleotider innenfor kodende regioner mye bedre enn de aller fleste andre mulige genetiske koder. Vi finner videre at evnen til å støtte parallelle koder er sterkt korrelert med en tilleggsegenskap – minimering av effektene av rammeskift-oversettelsesfeil."
 Den genetiske koden er dermed svært optimalisert for å kode tilleggsinformasjon utover aminosyresekvensen i proteinkodende sekvenser. Eksempler inkluderer RNA-spleisingssignaler og informasjon om hvor nukleosomer skal plasseres på DNA-et, samt sekvenser for RNAs sekundærstruktur.
Den genetiske koden er dermed svært optimalisert for å kode tilleggsinformasjon utover aminosyresekvensen i proteinkodende sekvenser. Eksempler inkluderer RNA-spleisingssignaler og informasjon om hvor nukleosomer skal plasseres på DNA-et, samt sekvenser for RNAs sekundærstruktur.
Det har også blitt vist i nyere arbeid at for mange proteinsekvenser ser det ut til at flere viktige fysisk-kjemiske egenskaper (som hydrofobisitetsprofiler) beholdes ved et +1 eller -1 rammeskift, og det har derfor blitt foreslått at "rammeskiftstabilitet er innebygd i strukturen til den universelle genetiske koden".(2) En annen artikkel forsøkte å måle i hvilken grad den konvensjonelle genetiske koden er optimalisert i forhold til tusenvis av alternative kodesett, inkludert rent tilfeldige koder samt koder som delvis bevarte strukturen til den konvensjonelle koden.(3)
Bilde 3. RNA benyttes bl.a. til å kopiere DNA
Spesielt undersøkte de virkningen av konservative mutasjoner på alternative leserammer – det vil si spørsmålet om aminosyrelikhet opprettholdes i alternative rammer når en mutasjon oppstår som resulterer i den samme eller en lignende aminosyre i den andre rammen. De bestemte at standardkoden var mest optimalisert, av kodene som ble undersøkt, i -1-rammen, selv om standardkoden også presterte bra i andre rammer.
Dette indikerer et ytterligere nivå av finjustering av den standard genetiske koden, for å muliggjøre overlapping av kodesekvenser. Artikkelen hevdet at "ikke en eneste kode bedre enn standardkoden ble funnet i 10^10 [dvs. ti milliarder] koder". Dette avslører et nivå av finjustering som overgår selv tidligere estimater.(4)
Problemet med mislykket avvisning
 En annen artikkel modellerer spesifisiteten til korrekt kodon-antikodon-dupleksdannelse under translasjon.(5) I følge modellen deres er det nødvendig at en feil dupleks har minst én ukompensert hydrogenbinding for at ribosomet skal avvises: et kriterium som gir vanskeligheter når duplekser har et par pyrimidiner (dvs. U eller C) i kodonets tredje posisjon, dvs. wobble-posisjonen. Pyrimidinbaser er noe mindre enn purinbaser (G og A), og i wobble-posisjonen kan de tillate at visse feilmatchninger i den andre posisjonen produserer ikke-Watson-Crick-par som kompenserer for de manglende hydrogenbindingene. Dette resulterer i en feiltranslasjonshendelse fordi feilmatchningene i den andre posisjonen ikke avvises riktig.
En annen artikkel modellerer spesifisiteten til korrekt kodon-antikodon-dupleksdannelse under translasjon.(5) I følge modellen deres er det nødvendig at en feil dupleks har minst én ukompensert hydrogenbinding for at ribosomet skal avvises: et kriterium som gir vanskeligheter når duplekser har et par pyrimidiner (dvs. U eller C) i kodonets tredje posisjon, dvs. wobble-posisjonen. Pyrimidinbaser er noe mindre enn purinbaser (G og A), og i wobble-posisjonen kan de tillate at visse feilmatchninger i den andre posisjonen produserer ikke-Watson-Crick-par som kompenserer for de manglende hydrogenbindingene. Dette resulterer i en feiltranslasjonshendelse fordi feilmatchningene i den andre posisjonen ikke avvises riktig.
Dette problemet kan omgås ved å forhindre at et antikodons pyrimidin i wobble-posisjonen danner et pyrimidinpar. En slik modifikasjon innebærer at et enkelt antikodon som kunne ha gjenkjent fire kodoner, nå bare er i stand til å gjenkjenne to. Så det må nå være ett tRNA for pyrimidinene i wobble-posisjonen og et annet tRNA for purinene i wobble-posisjonen.
Bilde 4. Aminosryrer bestemmer av 3 nukleotider (byggestener i RNA)
Dette forklarer hvorfor 32 kodoner (de som slutter med A og G) i den standard genetiske koden er i "familiebokser" (der alle fire kodonene spesifiserer den samme aminosyren) og de andre 32 (de som slutter med C og U) er i "delte bokser" (der de fire kodonene er delt mellom forskjellige aminosyrer). Faktisk bestemmer de samme stereokjemiske begrensningene som gjør det vanskelig for ribosomet å oppdage bestemte uoverensstemmelser i andre posisjon, også hvilke kodonbokser som må deles for å unngå disse feilene.
 Bilde 5. Kombinasjoner av kostnad/ytelse som fungerer i celler
Bilde 5. Kombinasjoner av kostnad/ytelse som fungerer i celler
Optimaliseringen av den genetiske koden er flerlags
I denne og tidligere artikler har vi undersøkt flere nivåer der den genetiske koden, langt fra å være en "frossen ulykke", ser ut til å være svært optimalisert på tvers av flere uavhengige begrensninger. Dette reiser et naturlig spørsmål: Hva forklarer disse fenomenene best? I den siste artikkelen i denne serien vil jeg vurdere de relative fordelene ved evolusjon og design som en forklaring på trekkene ved den genetiske koden.
For Referanser, se slutten av originalartiikelen -lenke.
.....................................
Den kombinatoriske avgrunnen: Hvorfor den genetiske koden trosser tilfeldighetene
Av Jonathan McLatchie 7. mai 2026, oversatt herfra
 I tidligere essays (her og her og ovenfor) har vi undersøkt ulike aspekter ved den genetiske koden som ser ut til å være svært optimalisert. Finjustering er så sterk at det knapt kan være en tilfeldig ulykke. Vi sitter dermed igjen med to valg – enten er den genetiske koden et resultat av prøving og feiling, drevet av naturlig seleksjon, eller så er den et produkt av bevisst design. I dette siste innlegget vil jeg vurdere hvilket av disse alternativene som er mest sannsynlig.
I tidligere essays (her og her og ovenfor) har vi undersøkt ulike aspekter ved den genetiske koden som ser ut til å være svært optimalisert. Finjustering er så sterk at det knapt kan være en tilfeldig ulykke. Vi sitter dermed igjen med to valg – enten er den genetiske koden et resultat av prøving og feiling, drevet av naturlig seleksjon, eller så er den et produkt av bevisst design. I dette siste innlegget vil jeg vurdere hvilket av disse alternativene som er mest sannsynlig.
Bilde 6. DNA-vindeltrappen (heliksen)
Låst på plass
Som jeg skrev i en tidligere artikkel om det optimaliserte settet med de tjue vanlige aminosyrene som finnes i livet, når den genetiske koden er etablert, og hver aminosyre er knyttet til spesifikke kodoner, tRNAer og aminoacyl-tRNA-syntetaser, blir den i hovedsak låst på plass – det vil si at den blir evolusjonært forankret (til tross for at det av og til er ekstremt små variasjoner i standardkoden). Faktisk ville betydelige modifikasjoner i koden skape kaos i cellen, siden omfordeling av forholdet mellom kodoner og aminosyrer ville påvirke hvert polypeptid som lages av cellen.
 Noen har forsøkt å argumentere rundt dette ved å hevde at de mindre brukte kodonene kan omdøpes til en annen, men beslektet aminosyre, slik at den genetiske koden kan optimaliseres. Det er imidlertid betydelige vanskeligheter med dette forslaget. For det første virker det svært usannsynlig at man, ved å erstatte noen av de mindre brukte aminosyretildelingene med en beslektet aminosyre, kan oppnå det optimaliseringsnivået som vi finner i den konvensjonelle koden.
Noen har forsøkt å argumentere rundt dette ved å hevde at de mindre brukte kodonene kan omdøpes til en annen, men beslektet aminosyre, slik at den genetiske koden kan optimaliseres. Det er imidlertid betydelige vanskeligheter med dette forslaget. For det første virker det svært usannsynlig at man, ved å erstatte noen av de mindre brukte aminosyretildelingene med en beslektet aminosyre, kan oppnå det optimaliseringsnivået som vi finner i den konvensjonelle koden.
Bilde 7. Ulike kodoner -tre 'byggestener' som bestemmer aminosyrer
Videre reiser man naturlig nok spørsmålet om hvilken selektiv nytteverdi de nye aminosyrene ville ha. De ville faktisk ikke ha noen nytteverdi før de er innlemmet i proteiner. Men det vil ikke skje før de er innlemmet i den genetiske koden. Og dermed må de syntetiseres av enzymer som mangler dem. Og la oss ikke glemme behovet for de dedikerte tRNA-ene og aktiverende enzymer som er nødvendige for å inkludere dem i koden.
En relatert vanskelighet
En relatert vanskelighet med standard evolusjonære forklaringer er at en pool av biotiske aminosyrer som er vesentlig mindre enn 20, er tilbøyelig til å redusere variasjonen av proteiner syntetisert av ribosomene betydelig. Og prebiotisk seleksjon vil sannsynligvis ikke sile variasjonskornet for denne egenskapen til aminosyreoptimalitet før opprinnelsen til selvreplikerende liv (på mange måter er "prebiotisk seleksjon" noe selvmotsigende).
Det er det ekstra problemet med potensialet for tvetydighet i kodonkartlegging. Hvis, for eksempel, 80 prosent av tiden et bestemt kodon spesifiserer én aminosyre og 20 prosent av tiden spesifiserer det en annen, vil denne tvetydigheten i kartleggingen føre til cellulært kaos.
 For en grundig diskursiv gjennomgang av ulike forsøk på å forklare kodeutvikling, henviser jeg leserne til en oversiktsartikkel av Eugene Koonin og Artem Novozhilov.(1) De avslutter sin kritiske gjennomgang med å beklage at:
For en grundig diskursiv gjennomgang av ulike forsøk på å forklare kodeutvikling, henviser jeg leserne til en oversiktsartikkel av Eugene Koonin og Artem Novozhilov.(1) De avslutter sin kritiske gjennomgang med å beklage at:
"Etter vår mening, til tross for omfattende og i mange tilfeller forseggjorte forsøk på å modellere kodeoptimalisering, genial teoretisering langs linjene med koevolusjonsteorien og betydelig eksperimentering, har det blitt gjort svært lite definitive fremskritt."
Bilde 8. Det trengs intelligent opphav for å omskrive kode
De rapporterer videre,
"Når vi oppsummerer den nåværende utviklingen innen studiet av kodeutvikling, kan vi ikke unngå betydelig skepsis. Det ser ut til at det todelte grunnleggende spørsmålet: "Hvorfor er den genetiske koden slik den er, og hvordan ble den til?", som ble stilt for over 50 år siden, ved molekylærbiologiens begynnelse, kan forbli relevant selv om 50 år. Vår trøst er at vi ikke kan tenke oss et mer grunnleggende problem innen biologi."
Likevel, selv om vi godtar premisset om at den genetiske koden kan endres over tid, gjenstår det å avgjøre om det finnes tilstrekkelige sannsynlighetsbaserte ressurser tilgjengelig til å rettferdiggjøre appeller til tilfeldighetenes og nødvendighetens virkemåte. I lys av det store antallet koder som må samples og evalueres, virker evolusjonære scenarier ganske usannsynlige.
Problemet med kombinatorisk rom
Det kombinatoriske rommet for genetiske koder er astronomisk stort – konservativt sett kan dette anslås til å være i størrelsesorden 10¹⁵ til 10²⁵. Dette forutsetter at kodongruppestørrelsene er faste – dvs. hvor mange kodoner som er tilordnet hver respektive aminosyre. Det forutsetter også at settet med aminosyrer som brukes av liv er begrenset til standard tjue. Uten noen av disse antagelsene er det kombinatoriske rommet mange størrelsesordener større.
For å gi en følelse av hvor stort dette kombinatoriske rommet er, bør man vurdere at for å komme frem til den standard genetiske koden  som finnes i naturen ved tilfeldig utvalg, ville dette kreve at mer enn 800 genetiske koder samples hvert sekund mellom livets opprinnelse og i dag {tilnærmet 10^18 sekunder siden). Selv om vi for øyeblikket ikke har et presist estimat av hvor utbredte genetiske koder som er like optimaliserte som den kanoniske koden er, er det sannsynlig at det er ganske sjeldent. For å sette dette i perspektiv, hvis vi konservativt antar at forekomsten av koder som er like høyt optimaliserte som den konvensjonelle koden er én av ti milliarder (selv om den faktiske forekomsten sannsynligvis er betydelig mindre enn dette), ville en genetisk kode i et tidsvindu på en million år måtte samples hvert femti-tredje minutt for å tilfeldigvis snuble over en av disse kodene. Det er ekstremt tvilsomt at dette kan oppnås ved et tilfeldig søk, gitt det sterke presset mot modifikasjoner av koden etter at den er etablert.
som finnes i naturen ved tilfeldig utvalg, ville dette kreve at mer enn 800 genetiske koder samples hvert sekund mellom livets opprinnelse og i dag {tilnærmet 10^18 sekunder siden). Selv om vi for øyeblikket ikke har et presist estimat av hvor utbredte genetiske koder som er like optimaliserte som den kanoniske koden er, er det sannsynlig at det er ganske sjeldent. For å sette dette i perspektiv, hvis vi konservativt antar at forekomsten av koder som er like høyt optimaliserte som den konvensjonelle koden er én av ti milliarder (selv om den faktiske forekomsten sannsynligvis er betydelig mindre enn dette), ville en genetisk kode i et tidsvindu på en million år måtte samples hvert femti-tredje minutt for å tilfeldigvis snuble over en av disse kodene. Det er ekstremt tvilsomt at dette kan oppnås ved et tilfeldig søk, gitt det sterke presset mot modifikasjoner av koden etter at den er etablert.
Bilde 9. Noen har ubegrenset tro på heldige omstendigheter
Ingen frossen ulykke
Selv om Francis Crick hevdet at den genetiske koden er en "frossen ulykke",(2) viser bevisene nå overveldende at standardkoden er høyt optimalisert på tvers av flere begrensninger. Av grunnene som er diskutert ovenfor, er det høyst usannsynlig at den genetiske koden kunne ha utviklet seg ved gradvis prøving og feiling. Gitt vår kunnskap om hva slags effekter som produseres av bevisste årsaker, er den utrolige og mangesidige finjusteringen langt mer sannsynlig under antagelsen om bevisst intensjon. Den genetiske kodens optimalitet peker derfor sterkt i retning av en intelligent skaper.
For Referanser, se slutten av originalartiikelen -lenke

JONATHAN MCLATCHIE
RESIDENT BIOLOG & stipendiat, SENTER FOR VITENSKAP OG KULTUR
Dr. Jonathan McLatchie har en bachelorgrad i rettsmedisinsk biologi fra University of Strathclyde, en mastergrad (M.Res) i evolusjonsbiologi fra University of Glasgow, en andre mastergrad i medisinsk og molekylær biovitenskap fra Newcastle University, og en doktorgrad i evolusjonsbiologi fra Newcastle University. Tidligere var Jonathan assisterende professor i biologi ved Sattler College i Boston, Massachusetts.
Bilde 10. Jonathan McLatchie
Jonathan har blitt intervjuet på podcaster og radioprogrammer, inkludert "Unbelieveable?" på Premier Christian Radio og mange andre. Jonathan har snakket internasjonalt i Europa, Nord-Amerika, Sør-Afrika og Asia for å fremme beviset for design i naturen.
Overrettelse med tillatelse fra Discovery Institute, ved Asbjørn E. Lund.